How to implement a robust machine learning platform
How to implement a robust machine learning platform
With the advances of AI and machine learning applications in almost every industry, many organizations are already jumping on the bandwagon of AI and investing in machine learning solutions. Many companies who are in the business of developing machine learning solutions, for their own use or for their clients start with defining the machine learning use case(s), identify data sources, build a suitable machine learning model, and then think about how to deliver that model and how to integrate it with their existing products. This makes the development of machine learning solutions very slow and inefficient with many repetitive work. A great number of machine learning teams have come to the conclusion that the process of developing such solutions should be automated through a platform that is standardized, robust, efficient and scalable.
In this blog post, I will share one of the AI/ML platform designs I worked on, with the tools and components used and how they integrate together. The technologies used are all open source and anyone can implement them for personal / learning purposes or commercial purposes.
Before we go into details, here is an overall diagram of the proposed architecture.
Every component is deployed as its own microservice. Kubernetes is used to deploy these components insure their scalability and high availability. It also manages the communication between these components and their exposure to outside traffic. Learn more Kubernetes and its features: https://kubernetes.io/docs/home/
Data sources
Every machine learning use case you are implementing will need to have a data source. Whether it is a database, a message queue, a sensor or a microservice… It is always necessary to identify your data sources before starting to design your machine learning platform.
Data pipelines
Data pipelines are necessary to continuously ingest the data from your production data sources and perform data cleaning, feature extraction, aggregations and any other transformations needed for making the data ready for your ML models. Here I am using Apache Kafka and Kafka connect as a real-time data pipeline but we can also have batch processing pipelines to process data incrementally following a schedule.
– Kafka
Apache Kafka is an open-source distributed streaming system used for stream processing, real-time data pipelines, and data integration at scale.
confluent.io/what-is-apache-kafka
To install Kafka on your Kubernetes cluster you can use Strimzi kafka operator which will facilitate the installation and configuration of Kafka and it’s components as well as Kafka connect on your Kubernetes cluster. You can install Strimzi kafka operator by cloning this repository. Using the files in /install/cluster-operator, specify the namespace and install them using kubectl create -f …
Once the Strimzi Operator is installed you can use one of the example yaml files in /examples/kafka, edit the name and namespace and perform a kubectl apply -f in the same namespace as the Strimzi operator.
– Kafka connect
Kafka Connect is the pluggable, declarative data integration framework for Kafka. In this architecture, kafka connect will allow us to connect to our databases and stream data to Kafka topics using source connectors. It will also allow us to stream data from kafka topics to any database using sink connectors. To install kafka connect framework we can use the same strimzi operator already installed. In the same repository, we can find examples of yaml files for kafka connect in /examples/connect.
You may need to add an ingress for your kafka connect to allow access to it from outside the cluster which will make it easier to create, update and delete connectors using API requests.
Kafka connect integrates with many data sources and databases. You can check the list of connectors here.
– Data preprocessing / Feature engineering
This is a major step in any machine learning solution. Data needs to be cleaned, the features needed for a certain machine learning model should be extracted, any aggregations or joins should be implemented and executed continuously. We can perform these operations using real time processing applications running continuously or scheduled batch processing jobs running according to a schedule.
Batch processing
Using Python scripts and Airflow, we can implement directed acyclic graphs (DAGs) that can read data from a data source, perform the necessary transformations and load the data back to our ML data pond to be later consumed by the machine learning algorithms. This processed is also referred to as ETL.
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
https://github.com/apache/airflow
Airflow can be deployed on Kubernetes using Bitnami helm charts.
Airflow can run schedule jobs locally (in the same pod), using celery executor, or using Kubernetes. The latter runs each task in their independent pods and allows to select any docker image and customize the configuration of the pods. Since each task is a pod, it is managed independently of the code it deploys and its dependencies. This is great for longer running tasks or environments with a lot of users, as users can push new code without fear of interrupting that task. This makes the k8s executor the most fault-tolerant option, as running tasks won’t be affected when code is pushed. It also allows data scientists to specify the dependencies for their projects without worrying about environment conflicts and updating dependencies every time.
Stream processing
“Stream processing has never been a more essential programming paradigm. Mastering Kafka Streams and ksqlDB illuminates the path to succeeding at it.”
-Jay Kreps, Co-creator of Apache Kafka and Co-founder and CEO of Confluent
When our data is streaming through our Kafka cluster, we need to be able to read that data and process it as it comes to the Kafka topics. Kafka provides data processing libraries for Python that allows you to read and write data from and to Kafka topics and perform any transformations in between. You can use libraries like Kafka-python or Faust to communicate with Kafka from Python scripts.
In terms of our architecture, the Python applications that process the streams will live in their own Kubernetes deployments. You can use a Miniconda image in a Kubernetes deployment and add a command to run your stream processing applications persisted in a git repository. For example your command can be something like:
git clone https://token_name:tokenp@ssword@your.reposi.tory.git --branch master
./yourrepositoryname/entrypoint.shAnd in your repository you have a entrypoint.sh that contains the scripts to be executed to run your streaming app, such as:
conda install requirement.txt
faust -A myapp worker -l infoMachine learning models’ training and packaging
Now that we have our data pipelines continuously ingesting and transforming data and making it available in our data pond, we can implement our machine learning algorithms and train our models. This process can take many attempts of model selection and parameter tuning. Therefore, a data scientist needs a tool to keep track of these attempts and the different versions of the resulting models as well as the dependencies used for each ML project. MLFlow is an open source technology that facilitate all that and more.
MLflow is an open source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
–https://mlflow.org/
MLflow currently offers four components:

In our architecture, we install MLflow server as a Kubernetes application using the helm chart here. Note that you need to have an SQL database as well as Minio installed and you must link the credentials to MLFlow installation using the configuration values. You may also want to add an ingress so that you can access the MLFlow server (and UI) from outside the cluster.
After committing your machine learning code where you have your MLFlow project, containing your model training, validation, packaging scripts using MLflow APIs and a dependencies file, you can run that project from a Kubernetes pod the same way you ran your data preprocessing scripts, using airflow. The architecture is the same except that this time you will instruct K8s to run the command mlflow run with the repository where your ML project resides and MLflow will take care of the rest, including packaging the model and storing it in Minio for portability. Airflow will allow you to schedule the training runs which will keep your model up to date. You can also go to the MLflow UI to observe the runs and their metrics over time.
Model deployment and serving
Once the MLFlow model is packaged and stored in Minio, you can serve it using MLFlow itself. However, I suggest the use of Seldon as a Serving technology because it offers extra features such as metrics, A/B testing and more.
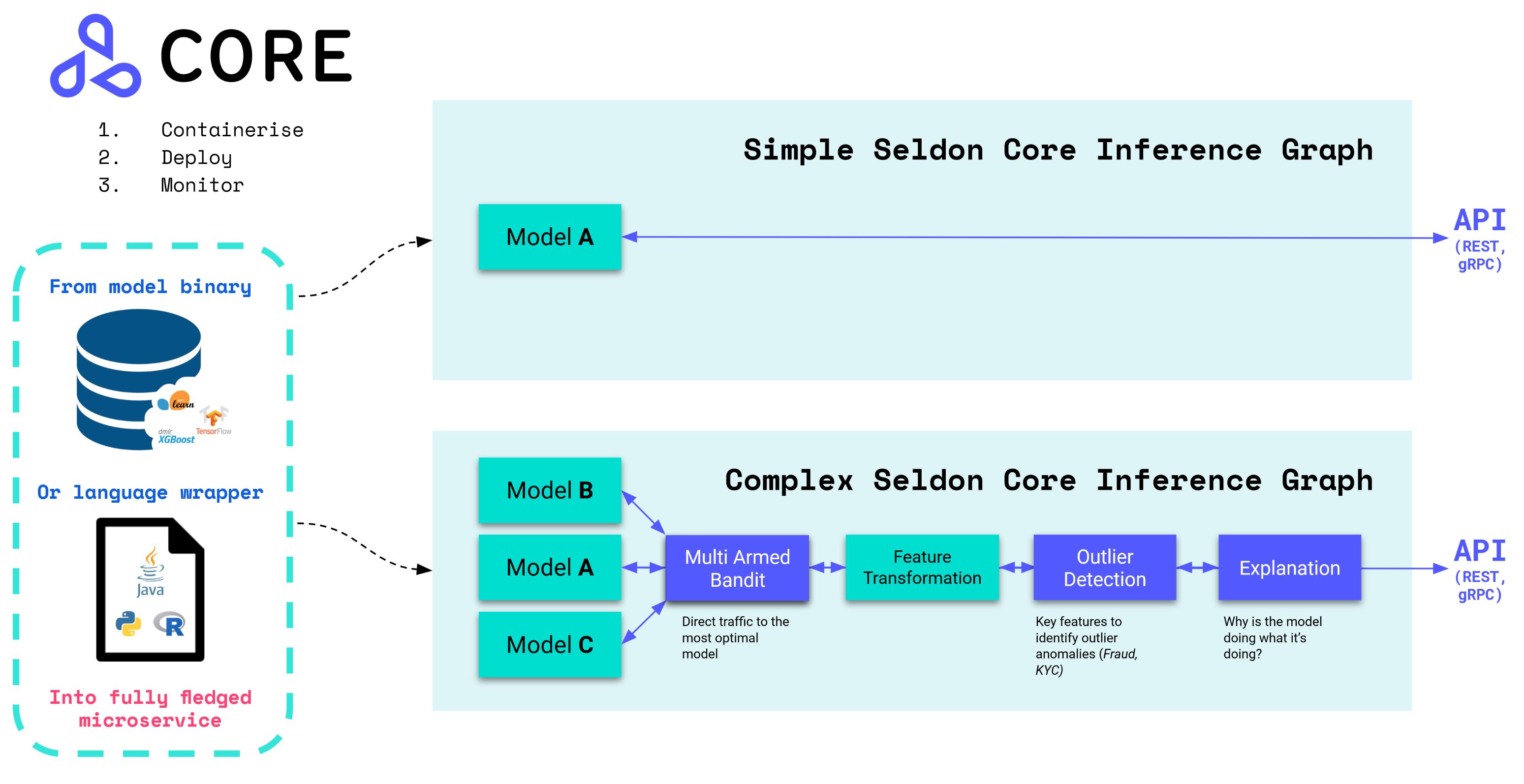
In our architecture in Kubernetes, you can install seldon-core operator using this helm chart. Once the operator is installed we can submit the seldon deployments as custom resource definitions (CRDs). For example this yaml file will deploy the machine learning model residing in <s3_endpoint>/mlflow-artifacts/3/420b5114806240a8ae514387571addda/artifacts/ourmodel. Note that you should specify the s3 (Minio) endpoint and credentials in a secret and reference it in this yaml file. In this case those credentials are stored in bpk-seldon-init-container-secret
apiVersion: machinelearning.seldon.io/v1alpha2
kind: SeldonDeployment
metadata:
name: model
namespace: serving-namespace
spec:
name: model
predictors:
- componentSpecs:
- spec:
containers:
- name: model
livenessProbe:
initialDelaySeconds: 300
failureThreshold: 1000
timeoutSeconds: 120
periodSeconds: 60
successThreshold: 1
tcpSocket:
port: 9000
readinessProbe:
initialDelaySeconds: 300
failureThreshold: 1000
periodSeconds: 60
successThreshold: 1
tcpSocket:
port: 9000
env:
- name: SELDON_LOG_LEVEL
value: DEBUG
graph:
children: []
implementation: MLFLOW_SERVER
modelUri: s3://mlflow-artifacts/3/420b5114806240a8ae514387571addda/artifacts/ourmodel
envSecretRefName: bpk-seldon-init-container-secret
name: model
parameters:
- name: xtype
type: STRING
value: DataFrame
name: default
replicas: 1
You can automate the deployment of Seldon deployments using a tool like Tempo in a Python script and have it triggered through an Airflow dag after the model training to ensure that the latest and/or the best models are deployed.
Monitoring
Once your models are deployed and running in production, you need to keep track of their core metrics as well as their performance. Seldon works smoothly with Prometheus and can expose out of the box metrics or custom metrics that can be scraped by Prometheus.
To set up Seldon metrics you need to have Prometheus running in your cluster. I recommend to configure Prometheus using Prometheus Operator. The kube-prometheus stack configuration can be easily installed using the Bitnami Helm Charts. Then you need to install and configure Seldon monitoring components and exporters as describe here.